

How Many Watts Does A Mini Split Draw?
How to split data into 3 sets (railroad train, validation, and test) And why?
Sklearn train test dissever is non enough. Nosotros need something improve, and faster

INTRODUCTION
Why exercise y'all need to split data?
You don't want your model to over-larn from training data and perform poorly later on being deployed in product. You need to take a mechanism to assess how well your model is generalizing. Hence, you lot demand to separate your input data into training, validation, and testing subsets to forestall your model from overfitting and to evaluate your model effectively.
In this post, we will cover the post-obit things.
- A brief definition of training, validation, and testing datasets
- Fix to use lawmaking for creating these datasets (2 methods)
- Understand the science behind dataset split ratio
Definition of Train-Valid-Test Separate
Train-Valid-Exam divide is a technique to evaluate the performance of your machine learning model — classification or regression alike. Y'all take a given dataset and divide it into three subsets. A brief description of the function of each of these datasets is below.
Train Dataset
- Set of data used for learning (by the model), that is, to fit the parameters to the automobile learning model
Valid Dataset
- Set of data used to provide an unbiased evaluation of a model fitted on the preparation dataset while tuning model hyperparameters.
- Also play a role in other forms of model training, such as feature selection, threshold cut-off option.
Test Dataset
- Ready of data used to provide an unbiased evaluation of a final model fitted on the training dataset.
Read this article by Jason Brownlee if y'all want to know more about how experts in machine learning define train, test, and validation datasets. Link in the references sections below #1
Ready to use code snippets
In this postal service we will see 2 ways of splitting the data into train, valid and exam set —
- Splitting Randomly
- Splitting using the temporal component
one. Splitting Randomly
Y'all can't evaluate the predictive functioning of a model with the aforementioned data you used for grooming. It would be best if you evaluated the model with new data that hasn't been seen by the model before. Randomly splitting the data is the most normally used method for that unbiased evaluation.
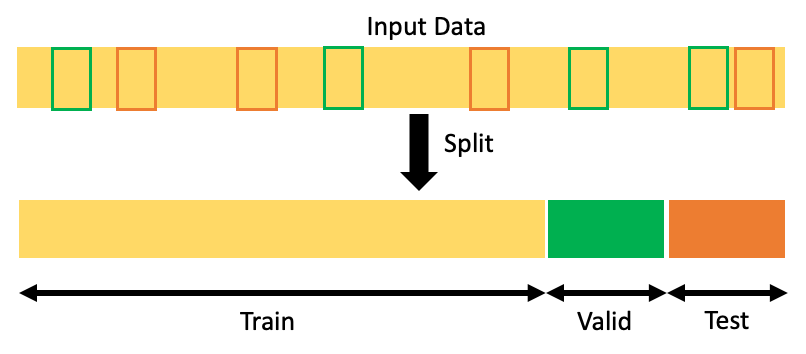
i. Using Sklearn → 'train_test_split'
In the code snippet below, you volition learn how to use train_test_split twice to create the train | valid | test dataset of our desired proportions.
two. Using Fast_ml → 'train_valid_test_split'
In the code snippet below, yous will learn how to utilise train_valid_test_split to create the train | valid | exam dataset of our desired proportions in a single line of code.
2) Splitting using the temporal component
You lot tin listen to Jeremy Howard in his fast.ai lectures on Machine Learning: Introduction to Machine Learning for Coders. In Lesson 3, he talks about "what makes a adept validation set, and we employ that discussion to selection a validation set for this new data." #2
He uses an example, "Let's say yous are building a model to predict next month's auction. And if you have no style of knowing whether the model you accept congenital is expert at predicting sales a month ahead of time, and then you accept no way of knowing when you lot put a model in product whether it's going to exist any skilful." #3
Using that temporal variable is a more reliable way of splitting datasets whenever the dataset includes the date variable, and we want to predict something in the futurity. Hence we must utilise the latest samples for creating the validation and examination dataset. The main idea is always choosing a subset of samples representing the data faithfully in our model will receive afterward (whether nosotros face a real-world problem or a Kaggle competition).
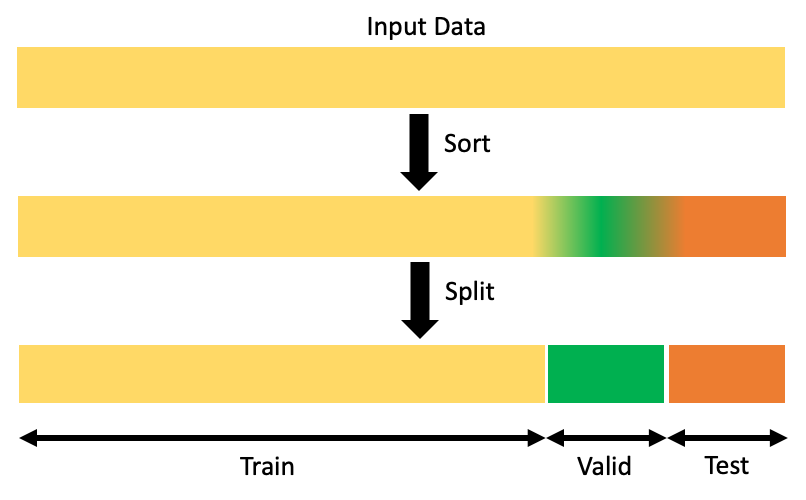
i. Custom code
In the code snippet below, you will acquire how to write your custom code to create the railroad train | valid | exam dataset of our desired proportions after sorting the data. You can utilize this lawmaking directly afterward the slight modifications.
ii. Using Fast_ml → 'train_valid_test_split'
In the code snippet below, you will acquire how to utilise train_valid_test_split to create the railroad train | valid | test dataset of our desired proportions subsequently sorting the data. All of that in merely a single line of code.
The science behind dataset split up ratio
Oft it is asked in what proportion to dissever your dataset into Train, Validation, and Exam sets?
This determination mainly depends on ii things. First, the total number of samples in your data, and second, on the actual model you are training.
- Some models need substantial data to railroad train upon, so you would optimize for the more all-encompassing training sets in this example.
- Models with very few hyper-parameters will be easy to validate and melody, so you can probably reduce the size of your validation prepare.
- Only if your model has many hyper-parameters, you would want to have a significant validation set likewise.
- If you happen to have a model with no hyper-parameters or ones that cannot exist easily tuned, you probably don't need a validation set too.
References
#1 https://machinelearningmastery.com/difference-exam-validation-datasets/ #2 https://world wide web.fast.ai/2018/09/26/ml-launch/
#three https://world wide web.youtube.com/lookout?v=YSFG_W8JxBo
Thanks for reading!!
- If you enjoyed this, follow me on medium for more than.
- Interested in collaborating? Let's connect on Linkedin.
- Delight feel free to write your thoughts/suggestions/feedback.
- Kaggle link
- Fast_ml link
Notebook is available at the following location with fully functional code:

Source: https://towardsdatascience.com/how-to-split-data-into-three-sets-train-validation-and-test-and-why-e50d22d3e54c
Posted by: andersonarou1937.blogspot.com
0 Response to "How Many Watts Does A Mini Split Draw?"
Post a Comment